[Day39] 양자화 & 지식 증류
[Day39] 양자화 & 지식 증류
중요
Fixed-point & Floating-point
Floating-point 방법을 더 많이 사용한다. 하지만 FPUs를 사용하는데 이것이 조금 무겁고 계산이 오래 걸린다.
Quantization
빠른 inference를 위해서
왜 딥러닝에서 양자화가 필요한지에 대한 내용은여기를 확인해 보면 좋을 것 같다.
양자화 mapping은 링크에서 확인 하자.
양자화까지 좋은데 이때 backwoard를 할 때 문제가 된다. 미분 불가능한 점들이 존재하기 때문에 smoothing을 통해서 해결 가능하다.
📌 Quantization 종류
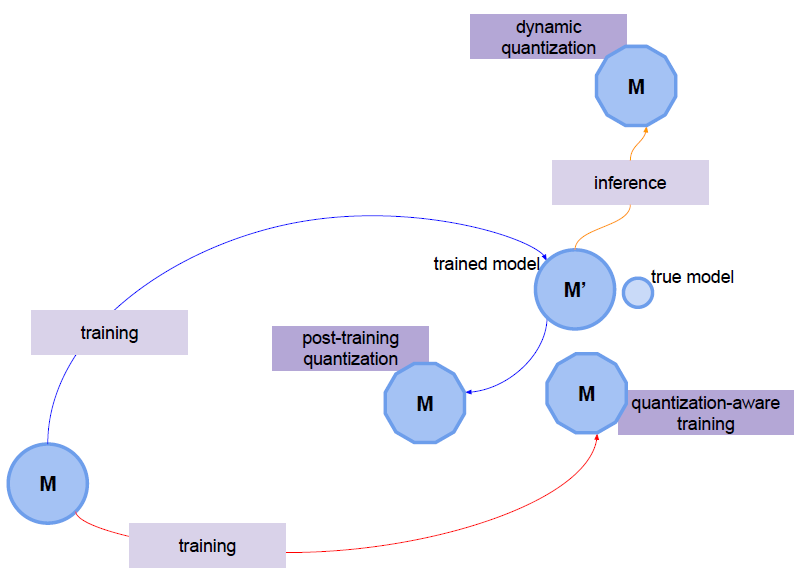
- Dynamic quantization(DQ): weight는 미리 양자화 되지만 activation은 inference동안 동적으로 양자화가 된다.
- Static quantization(PTQ): 정적 양자화는 Post Training Quantization 또는 PTQ라고 불린다.
- Quantization aware training(QAT): taining 시점에서 양자화가 됐을 때 loss가 어떻게 될 지 시뮬레이션를 같이 돌린다.
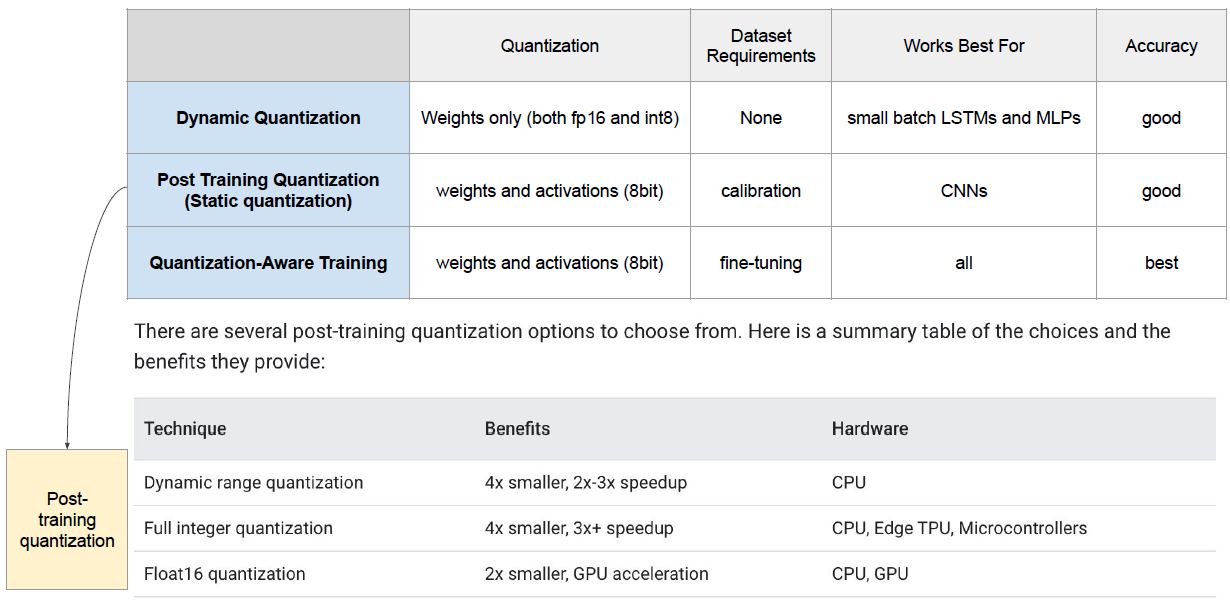
PTQ에 대해서는 좀 더 자세히 설명하고 있다. Hardware마다 지원 가능한 기술이 있으니 참고하자.
여기를 참고해 보면 좋을 것 같다.
Teacher-Student Network
여기서 혹시나 헷갈리는 부분이 있는데 Teacher-Student Network와 Transfer learning하고 어떻게 차이가 나는지 확인해 볼 필요가 있다. 차이는 Transfer learning은 예를 들어 영어 데이터는 많이 가지고 있는데 한국어는 영어보다 적게 가지고 있다고 가정해 보자. 그러면 영어에서 배운 지식을 어떠한 방법을 써서 한국어 domain에서 작동하게 만들 수 있느냐이다. 다른 domain끼리 작동한다면 Transfer learning이다.
하지만, Teacher-Student Network는 domain은 같다. 선생이 배운거랑 학생이 배울 domain은 같은거로 이야기 하는 것이다. 대신 여기서는 모델의 size를 작게 만드는데 초점이 있다. Teacher-Student Network의 자세한 내용은 여기에서 확인해 보자.
📌 Knowledge Distillation
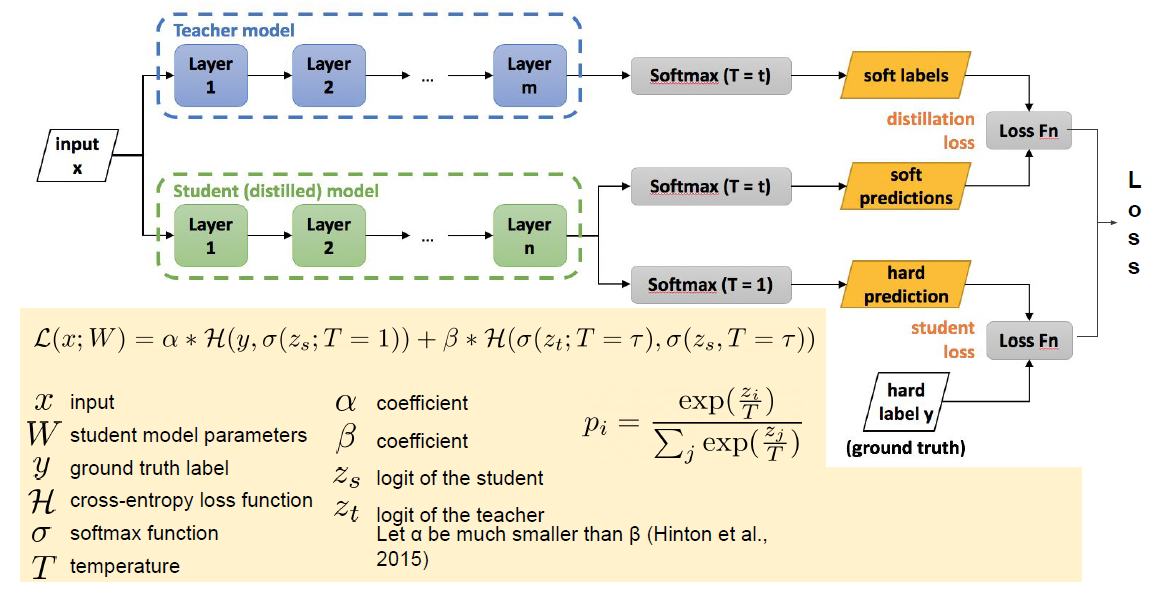
위 그림에서 보면 처음 보는 것이 등장하는데 soft labels, soft predictions라고 하는 단어가 등장한다.
우리가 흔히 사용하는 예측에서 Softmax는 hard prediction이 된다. 기존의 softmax는 가장 확률이 높은 class의 값만을 가지고 예측을 사용하게 되는데 이렇게 말고 모든 값들을 다 사용해서 예측을 해보자라는 개념이다.
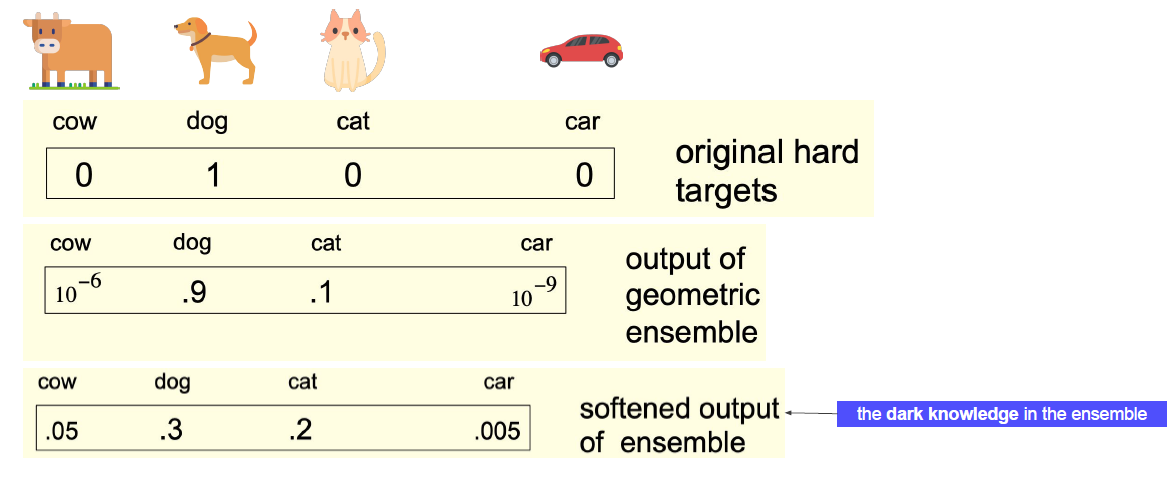
잘못된 출력의 상대적인 확률은 우리에게 모델이 어떻게 일반화될지를 알려준다. 다시말해 위에 예시에서 개의 확률 값만 사용하는 것이 아니라 개가 아닌 다른 class로 분류할 확률까지 같이 고려하여 주겠다는 의미이다. 자세한 내용은 논문을 확인해 보자.
📌 여러 종류의 Distillation
여러 가지 종류들이 존재하는데 여기를 통해서 각각의 종류들의 논문을 확인해 보면 좋겠다. 또 사용해보고 싶으면 각각의 종류에 git들의 link가 있는 여기를 확인해 보자.
몇 가지만 논문을 통해서 자세히 확인하자.
피어세션
- 백준 3584번: 가장 가까운 공통 조상 문제를 풀고 토론을 진행함
# 백준 3584번: 가장 가까운 공통 조상(LCA)
import sys
def find_nodelist(node,tree):
result=[node]
while tree[node] != 0:
result.append(tree[node])
node=tree[node]
return result
def solution():
T=int(sys.stdin.readline())
for _ in range(T):
N=int(sys.stdin.readline())
tree=[0]*(N+1)
for _ in range(N-1):
A,B=map(int,sys.stdin.readline().split())
tree[B]=A
node1, node2=map(int,sys.stdin.readline().split())
node1_List=find_nodelist(node1,tree)
node2_List=find_nodelist(node2,tree)
# 뒤 부터 탐색 무조건 root 노드부터 이기 때문에
pre=0
for a,b in zip(node1_List[::-1],node2_List[::-1]):
if a==b:
pre=a
else:
print(pre)
break
else:
print(pre)
solution()