[Day24] 정점 표현 & 추천 시스템(심화)
그래프의 정점을 어떻게 벡터로 표현할까?
그래프를 추천 시스템에 어떻게 활용할까? (심화)
중요
Node2Vec
import networkx as nx
from node2vec import Node2Vec
# 임의의 그래프 객체 값이 있다고 생각...
G = nx.Graph()
# edge 별 확률 계산(p, q에 따른 edge별 확률 계산) & random walk 생성
node2vec = Node2Vec(G, dimensions=16, walk_length=4, num_walks=200, workers=4)
# p = 1, q = 1 as default
# node embedding 구하기
model = node2vec.fit(window=2, min_count=1, batch_words=4)
여기 Node2Vec객체를 위와 같이 만들게 될 것이다. 이때 각각의 의미하는 인자들을 살펴보자. 여기서 G는 그래프 객체이다. 임의의 값이 있다고 생각하고 보자.
Node2Vec의 인자
graph: 입력으로 들어갈 그래프를 넣어준다.dimension: 임베딩 차원walk_length: random walk의 길이를 제한num_walks: 시작지점별 샘플링하는 random walk의 수를 지정workers: 사용하는 스레드 갯수 지정
model.fit의 인자
window: 임의보행 상에서 얼마나 가까이에 위치한 정점들을 유사한 것으로 보는지와 관련된 인자
잠재적 인수 모형
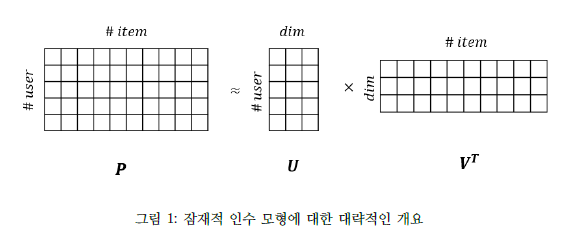
예를 들어, 5명의 사람(user)이 10개의 영화(item)에 평점을 매긴 데이터, 즉 원 평점 행렬 R이 있다고 가정해보자. 해당 원 평점 행렬 R은 그림 1처럼 5 × n, n × 10 크기의 두 행렬의 곱으로 표현될 수 있다.(n은 벡터의 dimension이고 편의상 n = 3으로 가정). 유저의 잠재 인수 행렬(latent factormatrix)을 U(5 × 3), 아이템의 잠재 인수 행렬을 V (10 × 3)라고 할 때, 예측 평점 행렬(predictedranking matrix) 은 아래와 같이 나타낼 수 있다.
예측 평점 P행렬의 i행 j열의 성분(entry)의 값은 i번 째 유저의 j번 째 아이템에 대한 평가를 의미하고, 수식으로 나타낸다면 Pij = Ui · Vj 가 된다. 예측 평점 Pij을 모든 유저, 아이템에 대하여 구한다면 예측 평점 행렬 P를 얻을 수 있게 된다. 그리고, 앞선 계산을 통해 얻어진 예측 평점 행렬 P가 원 평점 행렬 R과 유사해지는 방향으로 유저와 아이템의 잠재 인자 행렬 U, V를 업데이트 시킵니다. 이러한 과정을 통해서 얻게 되는 예측 평점 행렬 P을 토대로 유저에게 영화를 추천 하게된다.
📌 각 단계에서 필요한 함수들의 수도 코드이다.



피어세션
- 백준 17142번: 연구소 3 문제를 풀고 토론을 진행하였다.
import sys
from itertools import combinations
from copy import deepcopy
from collections import deque
def spread(virus,place):
global ans
q=deque()
check=[[0]*N for _ in range(N)]
time=0
for (i,j) in virus:
check[i][j]=1
q.appendleft((i,j))
while q:
for _ in range(len(q)):
x,y=q.pop()
for d in dir:
nx,ny=x+d[0],y+d[1]
if 0 <= nx < N and 0<= ny<N:
if lab[nx][ny] == '#' and check[nx][ny] ==0:
check[nx][ny] =1
place-=1
q.appendleft((nx,ny))
elif lab[nx][ny] == '*' and check[nx][ny] ==0:
check[nx][ny] = 1
q.appendleft((nx,ny))
time += 1
# 더 이상 전파 할 곳이 없으면
if place ==0:
ans = time
return
# 이미 시간이 있는데 time이 그 시간을 넘어 가면 더이상 전파 X
if ans <= time:
return
def search():
for select in combinations(virus, M):
spread(select, place)
N,M= map(int,sys.stdin.readline().split())
dir=[(1,0),(-1,0),(0,1),(0,-1)]
lab=[]
virus=[]
place=0
for i in range(N):
tmp=sys.stdin.readline().split()
# 들어온 입력 값을 수정하고 바이러스 위치 저장
for j in range(N):
if tmp[j] == '1':
tmp[j]='-'
elif tmp[j] == '0': # 빈곳은 '#'으로 표현
place+=1
tmp[j]='#'
else:
virus.append((i,j))
tmp[j]='*'
lab.append(tmp)
# 처음 부터 다 채워져 있는 경우
if place ==0:
print(0)
exit(0)
ans=float('inf')
search()
print(-1 if ans == float('inf') else ans)
'AI > 부스트 캠프 AI tech' 카테고리의 다른 글
| [Day30] AI + ML과 Quant Trading & AI Ethics (0) | 2021.03.05 |
|---|---|
| [Day29] NLP를 위한 언어 모델의 학습, 평가 & AI와 저작권법 (0) | 2021.03.04 |
| [Day28] 캐글 경진대회 노하우 & Full Stack ML Engineer (0) | 2021.03.03 |
| [Day27] 서비스 향 AI 모델 개발 & AI 시대의 커리어 빌딩 (0) | 2021.03.02 |
| [Day23] 군집 탐색 & 추천 시스템(기초) (0) | 2021.02.24 |
| [Day22] 페이지랭크 & 전파 모델 (0) | 2021.02.23 |
| [Day21] 그래프 이론 기초 & 그래프 패턴 (0) | 2021.02.22 |
| [Day20] Self-supervised Pre-training Models (0) | 2021.02.19 |