
[Day16] NLP 기초
Intro to NLP, Bag of Words
Word Embedding
중요
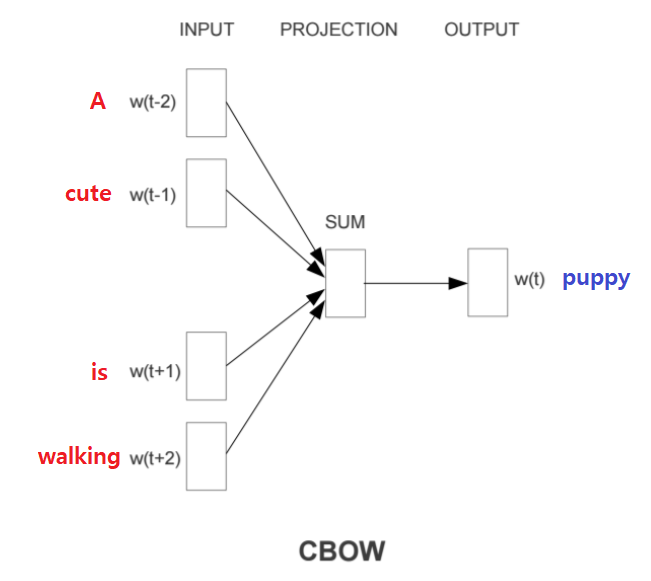
CBOW
주변 단어들을 가지고 중심 단어를 예측하는 방식으로 학습한다.
전체 과정은 다음과 같다.
- 주변 단어들의 one-hot encoding 벡터를 각각의 embedding layer에 projection한다.
- 각각의 embedding 벡터를 얻고 이 embedding들을 element-wise한 덧셈으로 합친다.
- 다시 linear transformation하여 예측하고자 하는 중심 단어의 one-hot encoding벡터와 같은 사이즈의 벡터로 만든 뒤, 중심 단어의 one-hot encoding 벡터와 같은 사이즈의 벡터로 만든다.
- 그 다음 중심 단어의 one-hot encoding 벡터와의 loss를 계산한다.
ex) A cute puppy is walking in the park. (
window size = 2)- Input(주변 단어): "A", "cute", "is", "walking"
- Outpu(중심 단어): "puppy"
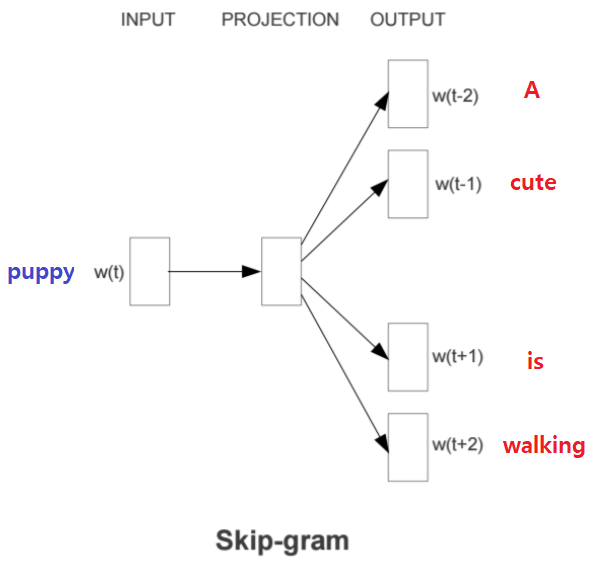
Skip-gram
중심 단어를 가지고 주변 단어들을 예측하는 방식으로 학습한다.
전체 과정은 다음과 같다.
- 중심 단어의 one-hot enoding 벡터를 embedding layer에 projection하여 해당 단어의 embedding 벡터를 얻는다.
- 이 벡터를 다시 linear transformation하여 예측하고자 하는 각각의 주변 단어들과의 one-hot encoding 벡터와 같은 사이즈의 벡터로 만든다.
- 그 주변 단어들의 one-hot encoding 벡터와의 loss를 각각 계산한다.
ex) A cute puppy is walking in the park. (
window size=2)- Input(중심 단어): "puppy"
- Output(주변 단어): "A", "cute", "is", "walking"
참고 자료
피어세션
- NaiveBayes Classifier계산식에 대해서 토론하였다.
- csv다루기 발표(죠르디)
- 기사 제목 생성기 발표(라이언)
'AI > 부스트 캠프 AI tech' 카테고리의 다른 글
| [Day20] Self-supervised Pre-training Models (0) | 2021.02.19 |
|---|---|
| [Day19] Transformer (0) | 2021.02.18 |
| [Day18] Seq2Seq (0) | 2021.02.17 |
| [Day17] LSTM and GRU (0) | 2021.02.16 |
| [Day15] Generative model (0) | 2021.02.05 |
| [Day14] RNN (0) | 2021.02.04 |
| [Day13] CNN (0) | 2021.02.03 |
| [Day12] 최적화 (0) | 2021.02.02 |