[Day17] LSTM and GRU
RNN and Language modeling
LSTM and GRU
중요
pack_padded_sequence
NLP에서 매 배치(batch)마다 고정된 문장의 길이로 만들어주기 위해서 <pad> 토큰 넣어야 한다. 아래 그림의 파란색 영역은 <pad> 토큰이다.

위 처럼 batch에 문장들을 배치하고 연산을 진행 하게 되면 계산이 필요없는 <pad> 토큰까지 연산을 진행 할 수 밖에 없다. 여기서 <pad>를 계산 안하고 효율적으로 진행하기 위해 아래와 같이 PackedSequence를 만든다.
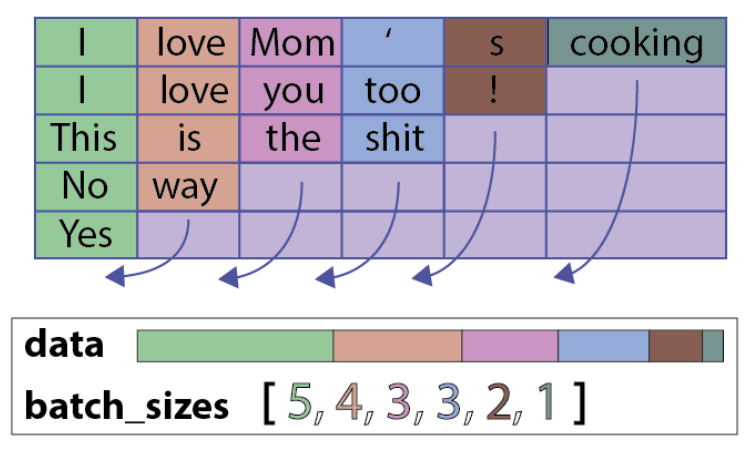
위 그림과 같이 배치내에 문장의 길이를 기준으로 정렬 후, 하나의 통합된 배치로 만들어 준다.
- data:
<pad>토큰이 제거후 합병된 데이터 - batch_sizes: 각 타임스텝 마다 배치를 몇개를 넣을지 기록
위 처럼 PackedSequence를 만들게 되면 <pad>토큰을 계산 안하기 때문에 더 빠른 연산이 가능하다.
참고자료
- https://simonjisu.github.io/nlp/2018/07/05/packedsequence.html
- 사진 출처:[Understanding emotions — from Keras to pyTorch]
Teacher forcing
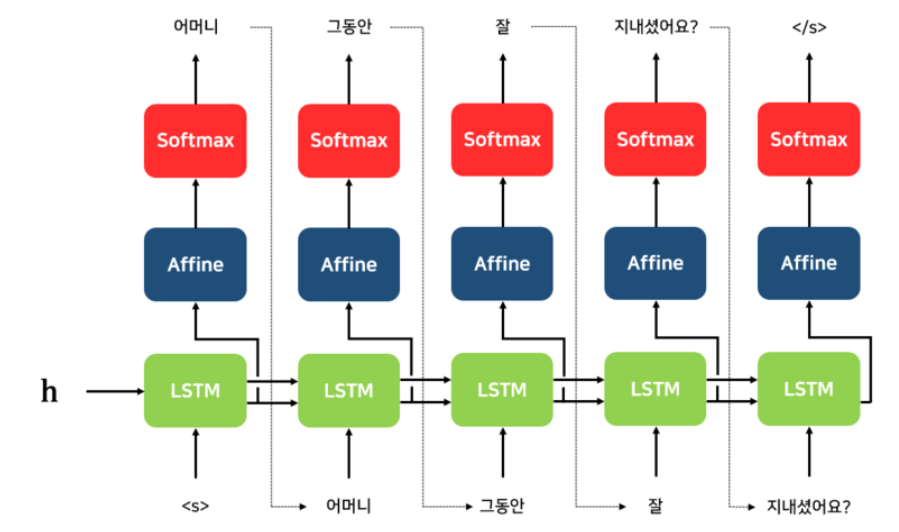
먼저 위의 Seq2Seq모델의 디코더를 보자.
t-1번째의 디코더 셀이 예측한 값을 t번째 입력으로 넣어준다. 이때 위처럼 t-1번째에서 정확한 예측이 이루어졌다면 상관 없지만, 잘못된 예측이 이루어졌다면 t번째 디코더의 추론 역시 잘못된 예측으로 이어질 것이다.
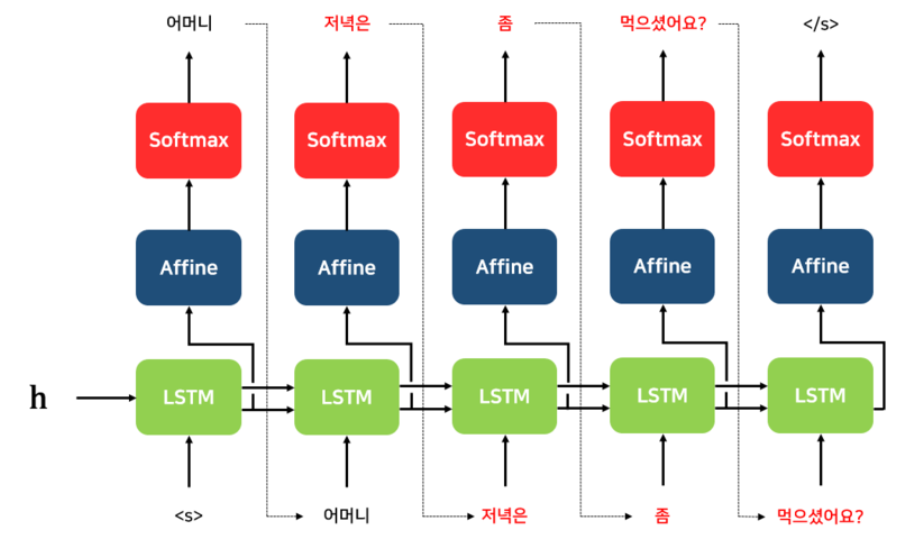
위 처럼 t-1번째에서 잘못된 예측이 됐다면 다음 입력값이 잘못 들어가기 때문에 출력도 잘못 나오게 된다. 이러면 학습 초기에 학습 속도 저하의 요인이 된다. 이러한 단점을 해결하기 위해 나온 기법이 티쳐포싱(Teacher Forcing) 기법이다.
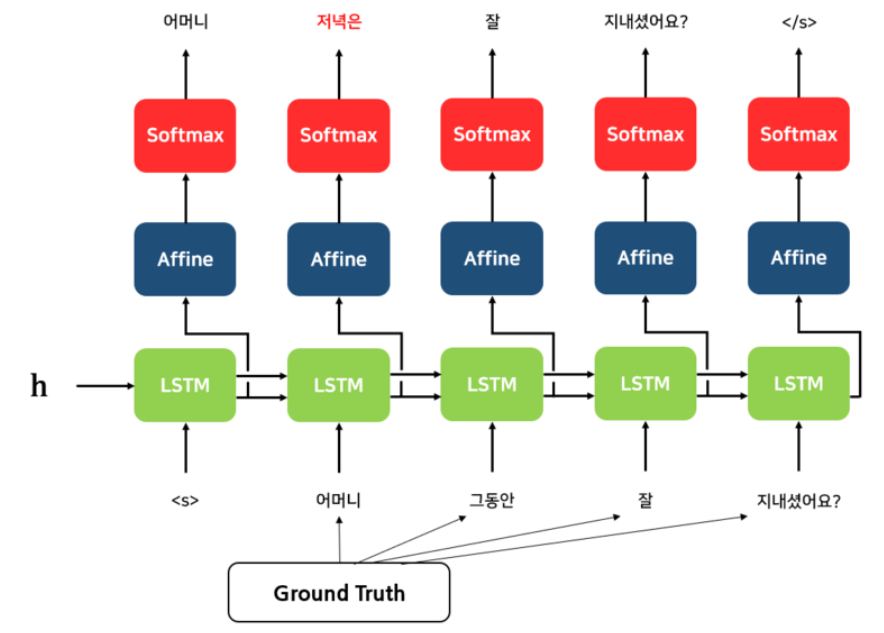
그래서 위와 같이 초기 입력값으로 Ground Truth 즉, 처음 정답 값을 넣어주게 되면 학습시 더 정확한 예측이 가능하게 되기 때문에 초기 학습 속도를 빠르게 올릴 수 있다.
피어세션
- 백준 1089번: 스타트링크 타워 문제를 토론하였다.
import sys
# 숫자 생성
sample='''\
###...#.###.###.#.#.###.###.###.###.###
#.#...#...#...#.#.#.#...#.....#.#.#.#.#
#.#...#.###.###.###.###.###...#.###.###
#.#...#.#.....#...#...#.#.#...#.#.#...#
###...#.###.###...#.###.###...#.###.###'''
sample_list=sample.split('\n')
number=[]
# 한 숫자씩 읽기
for std in range(0,4*10-1,4):
tmp=list(map(lambda x: x[std:std + 3], sample_list))
point=set()
for i in range(5):
for j in range(3):
if tmp[i][j] == '#':
point.add((i,j))
number.append(point)
def num_matching(board):
ans=[]
compare=set()
for i in range(5):
for j in range(3):
if board[i][j] == '#':
compare.add((i,j))
for n,n_set in enumerate(number):
# 불을 켜서 가능한 번호
if compare - n_set== set():
ans.append(n)
if not ans:
print(-1)
exit(0)
return ans
N=int(sys.stdin.readline())
result=0
info_board=[]
cases=[]
# 5줄로 입력을 받음
for _ in range(5):
info_board.append(sys.stdin.readline())
# N개의 숫자에 대해서 처리
for std in range(0,4*N-1,4):
cases.append(num_matching(list(map(lambda x: x[std:std+3],info_board))))
case_cnt=[len(l) for l in cases]
sum_cnt=1
for num in case_cnt:
sum_cnt*=num
for i,C in enumerate(cases):
cnt=1
for num in [n for j,n in enumerate(case_cnt) if j!=i]:
cnt*=num
for num in C:
result+=num*cnt*10**(N-i-1)
print(result/sum_cnt if sum_cnt !=0 else -1)
'AI > 부스트 캠프 AI tech' 카테고리의 다른 글
| [Day21] 그래프 이론 기초 & 그래프 패턴 (0) | 2021.02.22 |
|---|---|
| [Day20] Self-supervised Pre-training Models (0) | 2021.02.19 |
| [Day19] Transformer (0) | 2021.02.18 |
| [Day18] Seq2Seq (0) | 2021.02.17 |
| [Day16] NLP 기초 (0) | 2021.02.15 |
| [Day15] Generative model (0) | 2021.02.05 |
| [Day14] RNN (0) | 2021.02.04 |
| [Day13] CNN (0) | 2021.02.03 |