[Day37] 시간복잡도 & Compression
중요
NAS(Neural Architecture Search)
모델링을 자동으로 하는 신경망 아키텍쳐 탐색 기술이다. NAS는 검색 공간(search space), 검색 전략(search strategy), 성능 추정 전략(performance estimation strategy)의 세가지 측면으로 분류된다.
📌 검색 공간
검색 공간은 원칙적으로 표현할 수 있는 아키텍처를 정의한다. 적합한 아키텍처의 일반적인 속성에 대한 사전 지식을 사용하면 검색 공간의 크기를 줄이고 검색을 단순화 할 수 있다. 예를 들어 이미지 분류를 할 때에는 residual connection을 이용하여 residual block을 만들어 활용하면 좋을 것이라고 알려져 있다. 이 블록들로 구성한 아키텍처를 기반으로 신경망 아키텍쳐 탐색을 수행할 수 있다. 그러나 이것은 또한 인간의 편견을 도입하여 현재 인간의 지식을 넘어서는 새로운 아키텍처 구성 요소를 찾지 못한다.
📌 검색 전략
검색 전략은 검색 공간을 탐색하는 방법을 자세히 설명한다. 최고 성능의 아키텍처를 찾는 것과 차선의 성능의 아키텍처를 신속하게 찾는 것 사이에서 원하는 전략을 택해야 한다.
📌 성능 추정 전략
NAS의 목표는 일반적으로 보이지 않는 데이터에 대해 높은 예측 성능을 달성하는 아키텍처를 찾는 것이다. 성능 추정은 성능을 추정하는 프로세스를 나타낸다. 가장 간단한 옵션은 아키텍처에 대해서 표준 학습 및 검증을 수행하는 것이다. 하지만 이것은 불행히도 계산 비용이 많이 들고 탐색할 수 있는 아키텍처의 수가 제한된다. 따라서 많은 연구는 이러한 성능 추정 비용을 줄이는 방법을 개발하는 데 초점을 맞추고 있다.
참고자료
Depth-wise Separable Convolution
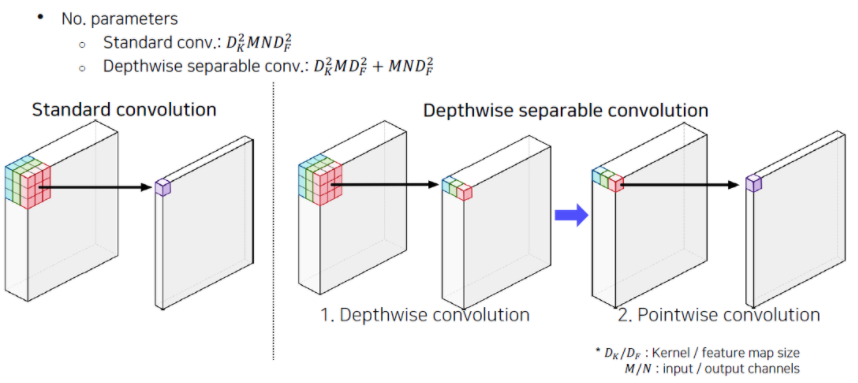
📌 Depthwise convolution
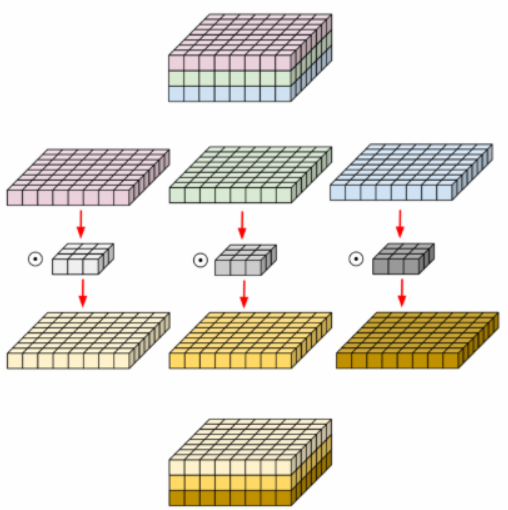
기본적인 개념은 위 처럼 HxWxC의 conv output을 C단위로 분리하여 각각 conv filter을 적용하여 output을 만들고 그 결과를 다시 합친다. 각 필터에 대한 연산 결과가 다른 필터로부터 독립적일 필요가 있을 경우에 특히 장점이 된다.
📌 Pointwise Convolution
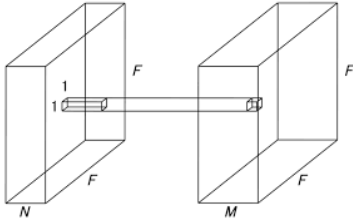
Depthwise convolution으로 만들어진 결과값에 흔히 말하는 1x1 Conv라고 불리는 필터를 사용하여 원하는 channel수로 맞춰주는 작업을 한다.
이렇게 2개의 연산으로 쪼개서 진행하게 되면 같은 정보를 가지고 있지만 더 적은 파라미터를 사용하게 된다.
KL divergence
먼저 이 개념을 알기 전에 Cross Entropy와 Entropy에 대해서 간단히 보고 넘어가자
📌 Entropy
📌 Cross Entropy
위 두 식 Cross Entropy를 보면 H(p,q)안에 이미 확률 분포 p의 Entropy가 들어있다. H(p)에 무언가 더해진 것이 Cross Entropy이다. 이때 이 무언가 더해지는 것이 바로 '정보량 차이'인데, 이 정보량 차이가 바로 KL-divergence이다. KL-divergence는 p와 q의 Cross Entropy에서 p의 Entropy를 뺀 값이다. 결과적으로 두 분포의 차이를 나타낸다.
이 식을 자세히 살펴보면 아래와 같다.
우리가 대게 Cross Entropy를 minimize 하는 것은, 어차피 H(p)는 고정된 상수값이기 때문에 결과적으로는 KL-divergence를 minimize하는 것과 같다.
📌 KL-divergence의 특성
피어세션
- 백준 16234번: 인구 이동을 풀고 토론함
'AI > 부스트 캠프 AI tech' 카테고리의 다른 글
| [Day41] EDA (0) | 2021.03.29 |
|---|---|
| [Day40] 행렬 분해 (0) | 2021.03.19 |
| [Day39] 양자화 & 지식 증류 (0) | 2021.03.18 |
| [Day38] 가속화 & pruning (0) | 2021.03.17 |
| [Day35] Muti-modal & 3D understanding (0) | 2021.03.12 |
| [Day34] Instance/Panoptic segmentation & Conditional generative model (0) | 2021.03.11 |
| [Day33] Object Detection & CNN Visualization (0) | 2021.03.10 |
| [Day32] Semantic Segmentation (0) | 2021.03.09 |