[Day38] 가속화 & pruning
중요
LLVM
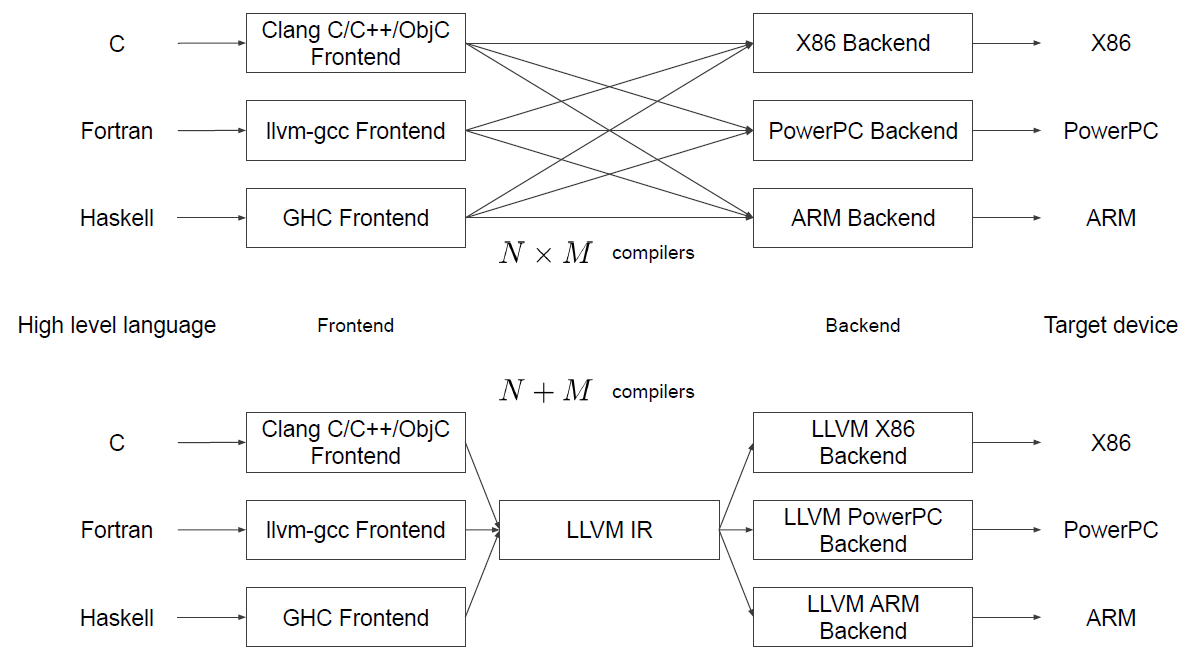
컴파일러는 프론트엔드-미들엔드-백엔드의 단계로 구성되어 있다. 보통 이 세 단계는 하나의 프로그램으로 일괄 처리되는데, 이럴 경우 '언어의 종류 x 아키텍처의 종류'만큼 복수의 컴파일러가 필요하게 된다. 다양한 언어와 다양한 아키텍처에 대응할 수 있는 이식성이 중요한 요즘 이러한 컴파일러 구조는 재사용성을 떨어뜨린다는 문제가 있다. 바로 이것을 해결할 수 있는 컴파일러 구조가 LLVM이다.
LLVM은 아키텍처별로 분리된 모듈식 미들엔드-백엔드를 중점으로 하고 있다. 프론트엔드가 여러가지 프로그래밍 언어들을 중간 표현 코드로 번역하고, LLVM은 그 중간 표현 코드를 각각의 아키텍처에 맞게 최적화하여 실행이 가능한 형태로 바꾸는 방식이다.
📌 Compiler
컴파일이란 어떤 언어의 코드를 다른 언어로 바꿔주는 과정. 대표적인 예는 C++ 코드를 기계어로 바꿔주는 것이다.
컴파일러를 엄밀히 말하자면, 어떤 프로그래밍 언어로 쓰여진 소스 파일을 다른 언어로 바꾸어주는 번역기 인 셈이다. 어떤 언어 A를 B로 바꾸면 그게 컴파일러다. Scheme을 C언어로 번역한다든지, 심지어 기계어를 C언어로 번역하더라도 컴파일러라고 칭할 수 있다. 하지만 대개의 경우 고수준 언어를 기계어로 번역하는 프로그램을 일컫는다.
참고 자료
Pruning
중요한 부분은 살리고 덜 중요한 부분은 가지 치기 한다.
얻는 것
- 추론 속도
- 일반화
잃는 것
- 정보 손실
- 세분성은 하드웨어 가속기 설계의 효율성에 영향을 준다.
📌 pruning vs Dropout
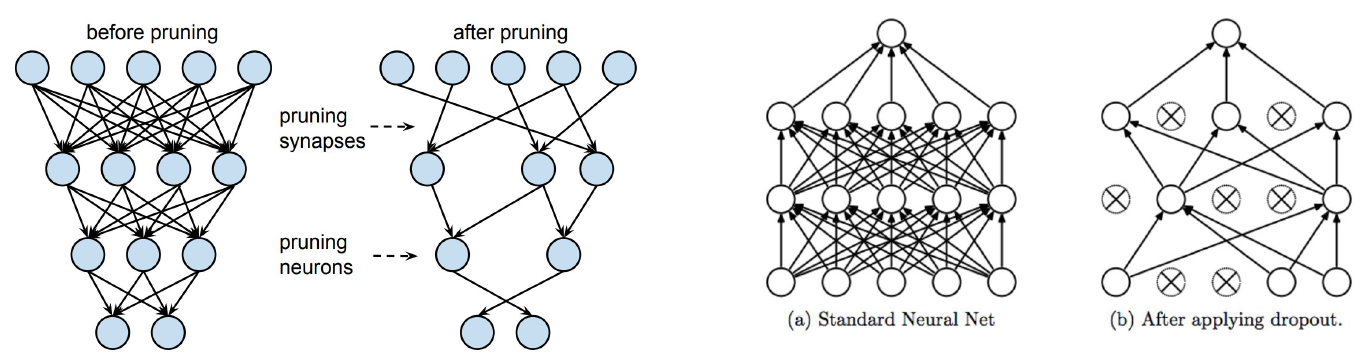
- pruning은 한번 잘라낸 weight는 복원하지 않는다.
- Dropout은 정규화가 목적이기 때문에 training할때 한번 껏다가 다음 epoch를 돌릴 때 켜는 작업을 하게 된다.
📌 pruning 방법
Iterative pruning
한번에 puning을 하게 되면 모델의 성능이 저하되고 다시 retraining해도 성능이 올라가지 않는다. 따라서 조금씩 덜어내서 다시 retraining하고를 반복해서 덜어 낸다.
Iterative pruning의 2가지 전략
- Iterative pruning with resetting
- Iterative pruning with continued training
자세한 내용은 논문의 p.14내용을 통해서 확인해 보자.
📌 Lottery Ticket Hypothesis
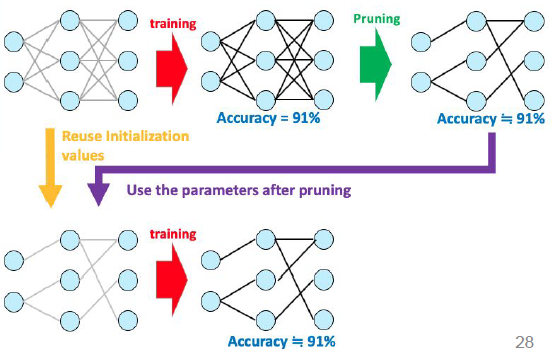
원래 네트웍크를 training을 하고 그다음 pruning을 진행한다.
그 다음 pruning을 진행한 네트웍크를 가지고 원래 네트웍크의 초기 weight를 가지고 다시 학습하면 그 정확도는 같을 것이라는 가설이다.
즉, 원래의 네트웍크안에 서브 네트웍크가 존재할 꺼라는 존재성에 대한 가설이다.
이때 서브 네트웍크는 원래의 네트웍크를 학습할 때 사용했던 초기 weight를 사용하지 않으면 정확도는 잘 나오지 않는다고 논문에서 제시한다.
📌 Iterative Magnitude Pruning
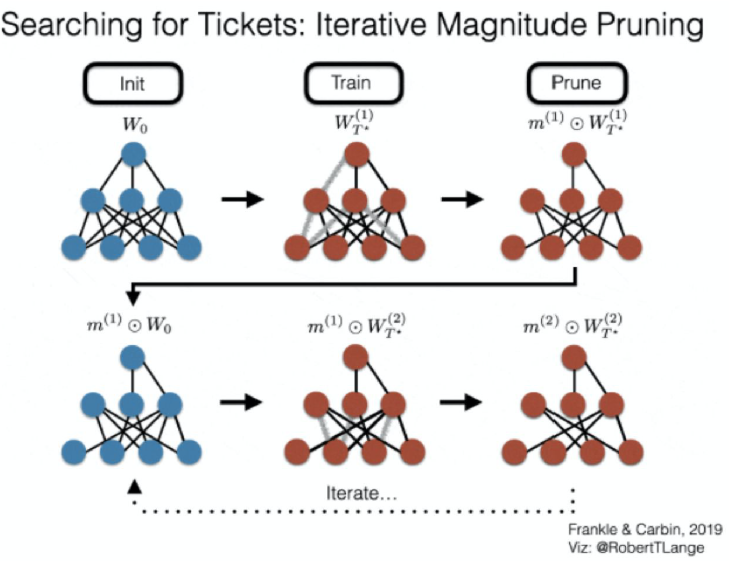
weight의 크기 기준으로 정렬해서 낮은 몇%를 짤라 낸다.
📌 Iterative Magnitude Pruning with Rewinding
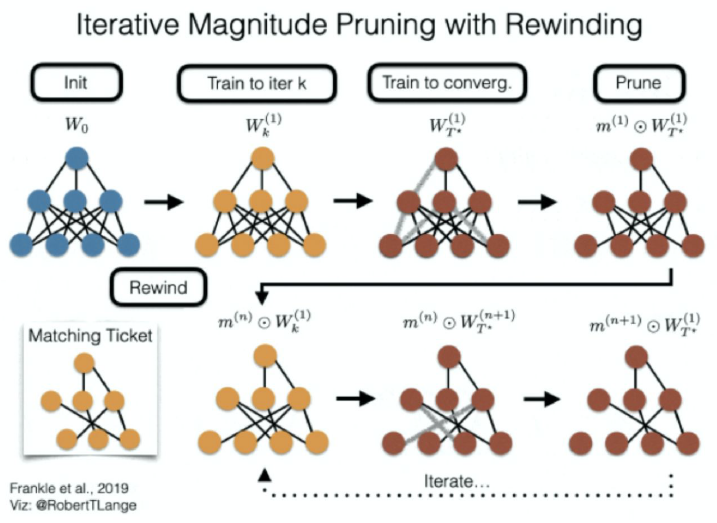
먼저 iter k 까지 돌고 그 상태의 weight를 저장해 둔다. 그 다음 T까지 weight을 수렴을 한다음 pruning을 진행하여 mask를 얻는다 이렇게 얻어진 mask를 가지고 초기 상태로 돌아 가는 것이 아니라 아까의 iter k의 wieght 상태로 돌아가서 여기서 mask랑 곱해서 새로운 weight로 다시 학습을 진행 한다.
처음 랜던하게 초기화 된 W0에서 iter k까지 학습을 진행하여 Wk을 얻는다. 그 다음 약간의 noise을 집어 넣어서 2가지 방향으로 학습을 시킨다. 왜냐하면 k에서 시작해서 똑같은 식으로 noise가 없이 반복하게 되면 rewinding하는게 의미가 없어진다. 같은 자리를 반복할 뿐이다. 랜덤성이 전혀 없으면 rewinding을 했다가 똑같이 학습을 하면 같은 결과가 나온다. 그래서 약간의 noise를 넣는다. 여기서 noise는 데이터의 순서를 바꾸는 정도의 약한 noise이다. 이 과정을 반복하는 것이다.
자세한 내용은 논문의 p. 4의 내용을 확인해 보자.
피어세션
찰스의 발표
- 7주차 CV 과제 2에 대해서 Classification하는 task로 pretrain된 VGG11모델의 fc layer의 weight를 segmentation 모델의 conv_out의 weight로 사용해도 꽤 괜찮은 결과가 나오는 이유에대해서 발표를 진행 하였다.