[Day40] 행렬 분해
중요
Kernel method
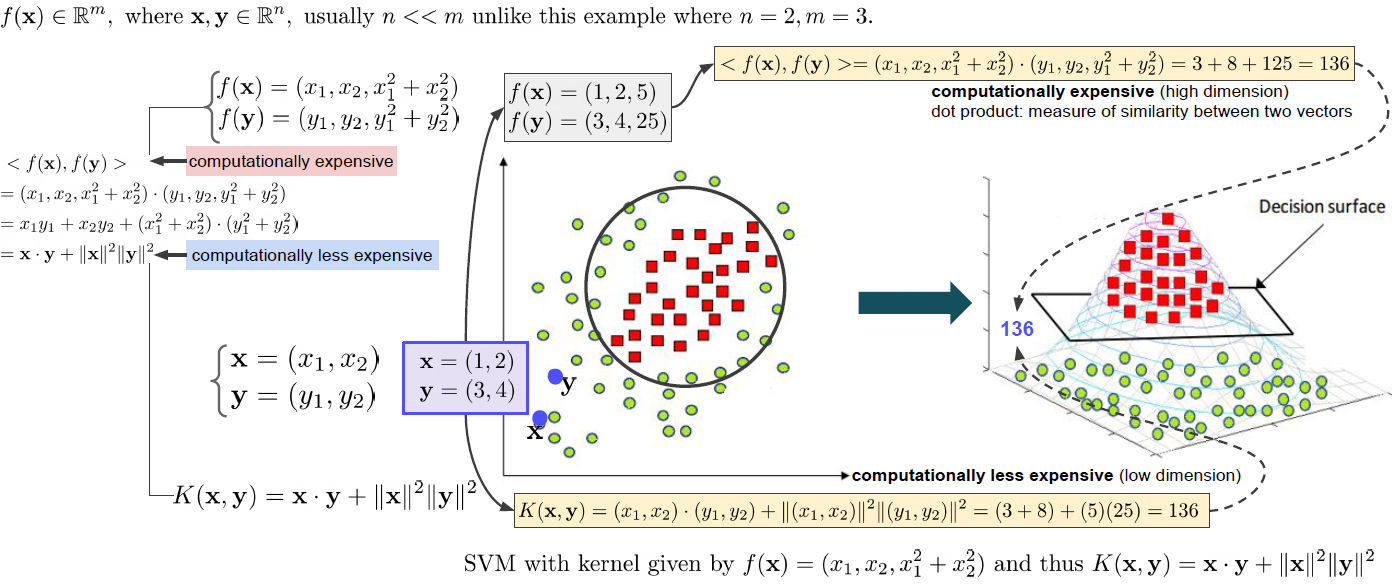
우리는 2차원 데이터를 위와 같이 분류 하고 싶다. 2차원에서 분류를 하게 되면 Decision surface를 결정하기 쉽지 않다. 하지만 고차원(그림에서 3차원)으로 보내 분류 작업을 진행하면 오른쪽 그래프와 같이 Decision surface를 정의할 수 있다. 그런데 이렇게 모든 점을 3차원으로 보내는 변환 작업을 진행하여 내적을 통한 유사도를 구하게 되면 많은 계산 비용이 든다. 그래서 우리는 kernel을 이용한다. kernel은 모든 점을 3차원으로 옮기는 변환을 진행하는 것이 아니라 3차원에서의 내적 계산 함수를 가지고있어서 원래 2차원의 두 점을 대입하면 바로 내적의 값을 얻을 수 있는 함수이다. 이렇게 되면 같은 결과를 내면서 더 적은 계산 비용을 가진다. kernel은 여러 분야에서 여러가지 기능으로 보고 있다. 왜 중요한가?
Matrix decomposition
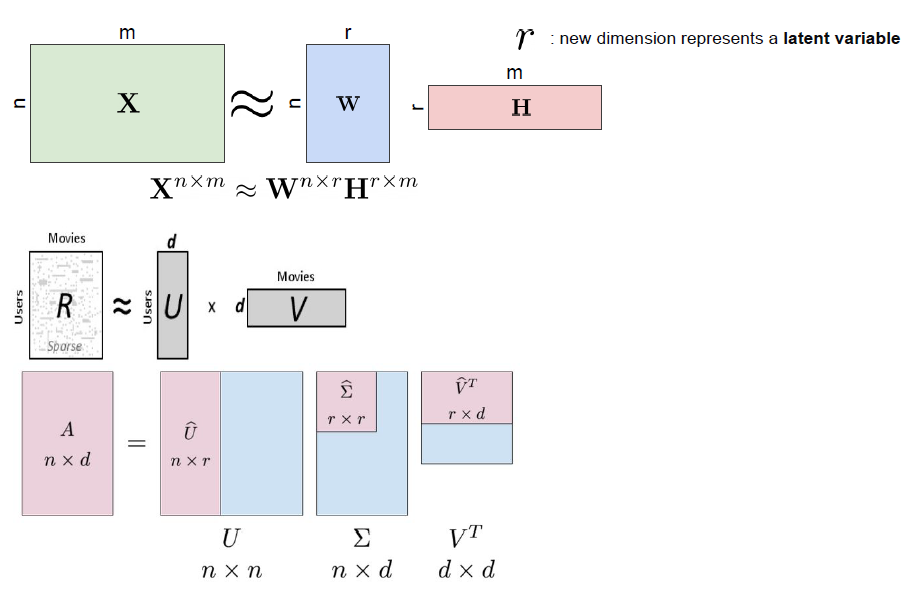
보통 이렇게 행렬 분해를 통해서 parameter의 수를 줄이게 되는데 추천 시스템에서 많이 사용하게 된다. 자세한 내용은 여기를 참고해 보면 좋을꺼 같다. 또한 CNN에서도 가속화 알고리즘에 parameter수를 줄이는데 사용한다.
Eigenvalue Decomposition
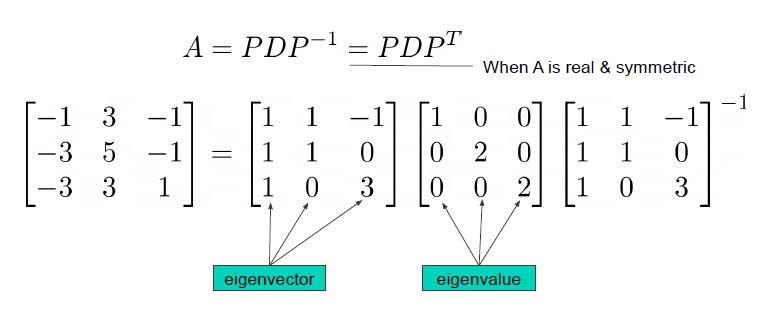
행렬의 위와 같이 분해 할 수 있는데 A가 특정 조건에 맞으면 A의 역행렬 대신해서 A의 전치행렬로 계산이 가능하다. 위와 같이 분리되는 자세한 과정은 아래 링크를 확인해 보면 좋을 것 같다.
참고 자료
- https://en.wikipedia.org/wiki/Diagonalizable_matrix
- https://en.wikipedia.org/wiki/Eigenvalues_and_eigenvectors
- Eigenvalues ans Eigenvectors 여기 유튜브를 보면 좋다.
Sigular Value Decomposition (SVD)
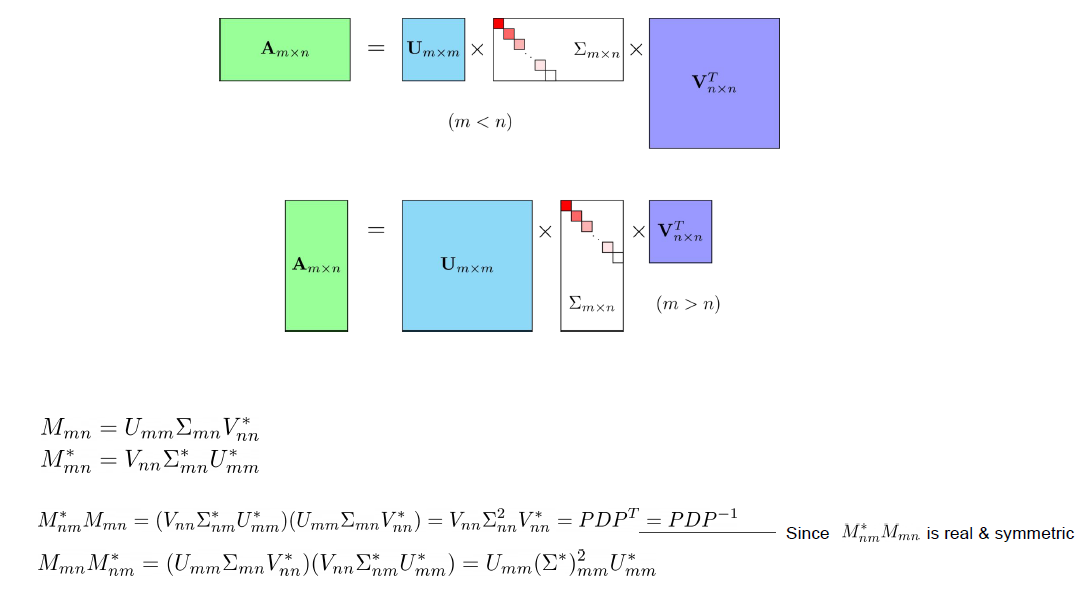
특이값 분해(SVD)는 해당 행렬의 행과 열의 크기 관계에 따라서 조금 다르게 나뉘게 된다. 이 과정의 자세한 내용은 여기를 참고하면 좋을 것 같다.
SVD의 기하학적의미로 살펴 보면,
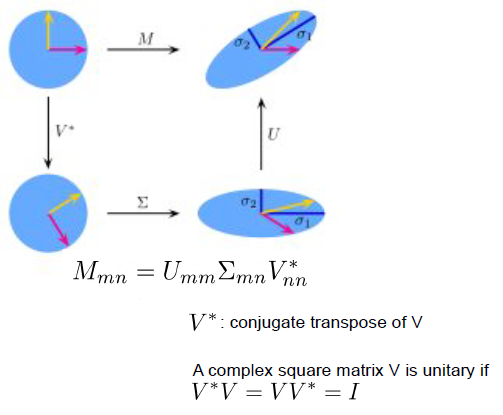
원래의 M변환을 3개의 변환으로 나눠서 생각할 수 있다. 이때 위에 변환 그림을 보면 V부터 U로 차례로 변환이 일어나는데 이것은 행렬 곱이 가장 끝 오른쪽에 V행렬부터 곱해진 것으로 의미를 확인할 수 있다. 행렬곱을 잘 생각해 보자.
PCA
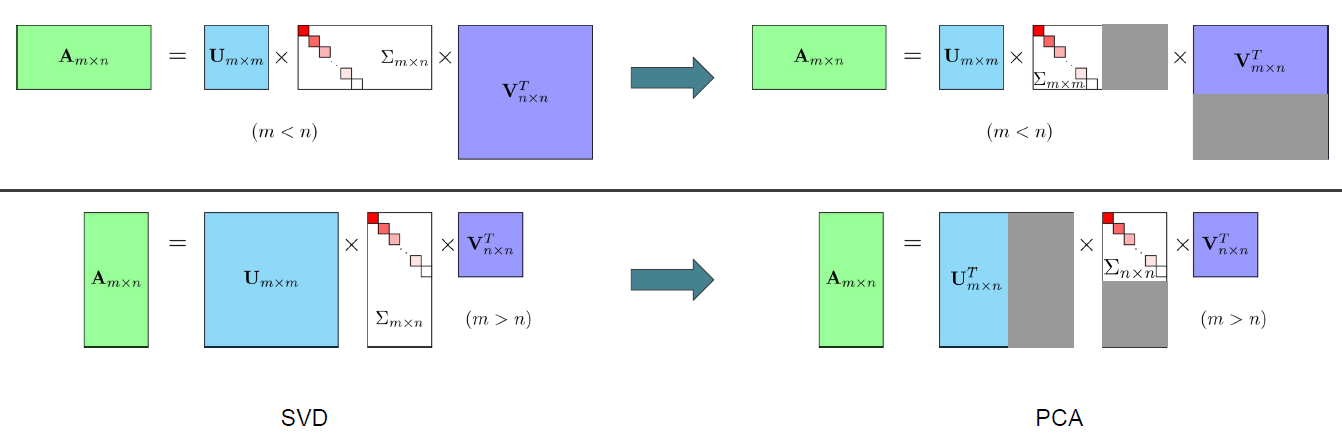
SVD에서 중요한 부분만 남기고 필요없는 부분은 잘라내는 것이 PCA이다.
이것 말고도 여러가지 decompositions의 방법이 있다. Truncated SVD, Canonical Polyadic Decomposition(CPD), Tucker Decomposition(TKD), Non-negative matrix Factorization(NMF) 등이 있다.
피어세션
- 강의를 듣고 CNN에 대해서 정리하여 발표를 하였다(죠르디)
- 앙사블 기법과 KLDivloss함수가 어떻게 작용하는지 발표 하였다.(라이언)
'AI > 부스트 캠프 AI tech' 카테고리의 다른 글
| [Day44] Training & Inference (0) | 2021.04.03 |
|---|---|
| [Day43] Model (0) | 2021.03.31 |
| [Day42] Data Feeding (0) | 2021.03.31 |
| [Day41] EDA (0) | 2021.03.29 |
| [Day39] 양자화 & 지식 증류 (0) | 2021.03.18 |
| [Day38] 가속화 & pruning (0) | 2021.03.17 |
| [Day37] 시간복잡도 & entropy (0) | 2021.03.16 |
| [Day35] Muti-modal & 3D understanding (0) | 2021.03.12 |