[Day42] Data Feeding
오늘 한 일
먼저 기본 baseline에 있는 모델을 통해서 정확도를 확인해 보았다.
- epochs=10, lr=0.0001의 결과 정확도는 11.62% 나왔다.
다음으로 epochs=100을 놓고 다시 학습한 결과
- 정확도는 13.25%가 나왔다.
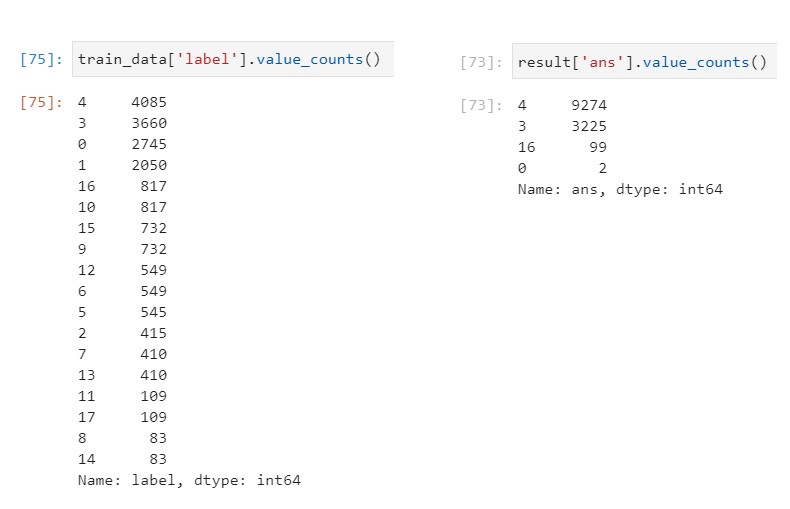
위 그림에서 결과를 볼 수 있듯이 데이터의 class가 4,3,0,1 순으로 많이 몰려 있는 것을 볼 수 있다.
이렇게 학습한 결과 오른쪽과 같이 결과에도 4,3이 많이 예측한 것을 볼 수 있다. 이 문제를 해결하기 위해서 다른 class의 학습 데이터들이 더 필요하다는 것을 확인할 수 있다.
✅ 어떻게 더 많은 데이터를 확보할 것인가?
- 가장 먼저 많이 없는 class에 대해서 data augmentation을 진행한다.
- 우선 대부분의 데이터가 마스크를 착용한 데이터가 많으므로 마스크를 착용하지 않은 외부 데이터를 사용한다.
- batch로 데이터를 넣어 줄 때 class별로 균등하게 넣어줘서 해결해 보자.
모델 저장 & 불러오기
- 여기를 참고하자.
- 전체 모델을 저장하기
max_pool2d
내일 할 일
- 데이터를 추가로 확보하여 학습을 진행 한다.
- 데이터가 적은데 시간이 많이 걸리는 이유는 dataset를 만들 때 그때그때 이미지를
open()하는 작업을 진행하게 되는데 여기서 많은 시간이 소요된다. 따라서 메모리가 된다면 먼저 CPU에 올리고 진행을 하게 되면 빠르게 학습을 끝낼 수 있을 것 같다. - 더 큰 모델을 통해서 학습을 진행한다.
- 분류 모델 3개를 따로 만들어 학습하고 취합하는 방식을 생각해 본다.
'AI > 부스트 캠프 AI tech' 카테고리의 다른 글
| [Day44] Training & Inference (0) | 2021.04.03 |
|---|---|
| [Day43] Model (0) | 2021.03.31 |
| [Day41] EDA (0) | 2021.03.29 |
| [Day40] 행렬 분해 (0) | 2021.03.19 |
| [Day39] 양자화 & 지식 증류 (0) | 2021.03.18 |
| [Day38] 가속화 & pruning (0) | 2021.03.17 |
| [Day37] 시간복잡도 & entropy (0) | 2021.03.16 |
| [Day35] Muti-modal & 3D understanding (0) | 2021.03.12 |