[Day43] Model
새로운 모델을 짜서 학습을 시켜보자. 이때 학습에 시간을 줄이기 위한 방법을 생각하자.
오늘 한 일
-
- Dataset을 직접 만들어서 각 iter마다 데이터를 불러오는데 시간을 줄이기
DataLoader에 대한 실험
아래 값은 고정으로 두고 실험을 진행
epochs= 5batch_size=32
# Dataset은 고정
class imgDataset(Dataset):
def __init__(self, img_paths, transform):
self.img_paths = img_paths['image_path']
self.labels=img_paths['label']
self.transform = transform
def __getitem__(self, index):
image = Image.open(self.img_paths[index])
label=self.labels[index]
if self.transform:
image = self.transform(image)
return image, label
def __len__(self):
return len(self.img_paths)
# transform 정의
transform = transforms.Compose([
Resize((512, 384), Image.BILINEAR),
ToTensor(),
Normalize(mean=(0.5, 0.5, 0.5), std=(0.2, 0.2, 0.2)),
])
📌 1. num_workers=1로 두고 측정
# dataset 만들기
train_dataset=imgDataset(train_data,transform)
train_loader=DataLoader(train_dataset,batch_size=batch_size,num_workers=1)
%%time
from tqdm import tqdm
print('Train start!!')
for epoch in tqdm(range(epochs)):
train_loss=0
for iter,(img,label) in enumerate(train_loader):
# GPU 연산을 위해 이미지와 정답 tensor를 GPU로 보내기
img,label=img.float().to(device),label.to(device)
# 모델 이미지 forward
pred_logit=model(img)
# loss 값 계산
loss = criterion(pred_logit, label)
# optimizer에 저장된 미분값을 0으로 초기화
optimizer.zero_grad()
# Backpropagation
loss.backward()
optimizer.step()
train_loss+=loss.item()
train_loss=train_loss/len(train_loader)
print("Epoch[{}/{}], Train Loss:{:4f}".format(epoch+1,epochs,train_loss))
<결과>

한 loop당 141초가 걸리는 것을 확인 할 수 있다.
📌 2. num_workers=4로 두고 측정
<결과>

한 loop당 38초가 걸리는 것을 확인 위 결과와 비교하여 많은 시간이 줄어든것을 확인 할 수 있다.
📌 3. num_workers=4 & pin_memory = True
<결과>
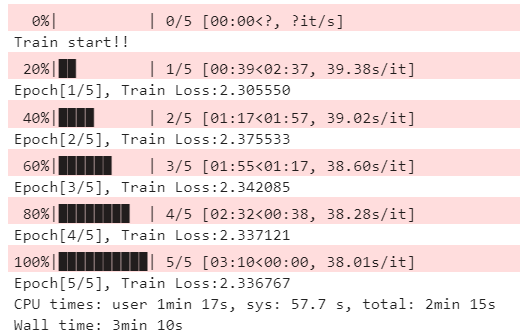
위 결과는 GPU 메모리가 충분해서 그런지 많은 차이가 발생하지 않았다.
MaxPool2d vs AdaptiveMaxPool2d
- 여기를 참조해서 보자.
불균형한 class의 DataLoader사용하는 방법
불균형한 경우 batch_size만큼 데이터를 뽑을 때 가중치를 주어서 뽑으면 어느 정도 해결이 가능하다.
이때 이용하는 것이 WeightedRandomSampler이다. 내용을 확인해보고 적용해 보았다.
✅ 배치가 균등하게 뽑아서 학습하고 부족한 부분을 넣어주기 전에 정확도를 측정한 결과

- 저번 대비 3% 정도 증가한 것을 확인 할 수 있다.
✅ 부족한 class에 중복으로 행을 더 넣어 준다. 이때는 augmentation을 진행하지 않았다.
결과를 보게 되면
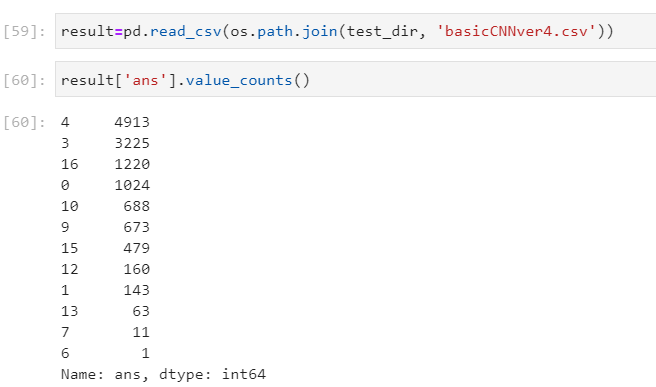
전에는 예측하지 못했던 class들도 예측을 하기 시작했다. 이것은 확실히 데이터가 부족하여 일어난 것이기 때문에 부족한 부분에 class를 더 늘려주면 더 좋은 정확도가 예측된다.

정확도는 전 보다 낮아 졌지만 이는 당연히 같은 이미지로 학습을 진행하였기 때문이고 f1의 score같은 경우는 더 증가 한 것을 볼 수 있다.
Feature Extraction 시도 (Backbone Freeze)
이 방법을 사용할 때는 backbone에 있는 parameter들은 required_grad=False로 두고 학습을 진행하면 된다.
timm이라는 라이브러리 패키지를 이용하면 좀 더 많은 모델을 사용할 수 있다.
내일 할 일
- 더 큰 모델을 돌리고 내일 확인해 보기
- Data augmentation을 진행하여 모델 학습하기
- 부족한 class에 대해서 더 많은 데이터를 사용하기
'AI > 부스트 캠프 AI tech' 카테고리의 다른 글
| [Day44] Training & Inference (0) | 2021.04.03 |
|---|---|
| [Day42] Data Feeding (0) | 2021.03.31 |
| [Day41] EDA (0) | 2021.03.29 |
| [Day40] 행렬 분해 (0) | 2021.03.19 |
| [Day39] 양자화 & 지식 증류 (0) | 2021.03.18 |
| [Day38] 가속화 & pruning (0) | 2021.03.17 |
| [Day37] 시간복잡도 & entropy (0) | 2021.03.16 |
| [Day35] Muti-modal & 3D understanding (0) | 2021.03.12 |